- - КАК ОПОЗНАТЬ ту или иную кодировку?
- - ЧТО ДЕЛАТЬ с письмом, чтобы прочитать текст (данные)?
- - ГДЕ ВЗЯТЬ необходимые программы?
- Передача почты и проблемы кодировок
- Передача почты и проблемы кодировок (простыми словами)
- В какой кодировке следует посылать письма?
- Кодировка KOI-8 или Windows
- Принцип кодирования в UUENCODE и BASE64.
- Кодировка UUENCODE
- Кодировка MIME (base64)
- Кодировка Quoted-Printable
- Кодировка BinHex
- Кодировка Xbtoa
- Кодировка PGP
- Упакованный "пакет статей"
Посмотреть на форуме.
Существует различие, что мы передаём в электронном письме - какого типа его содержание, и как мы это передаём - как это содержание кодируется.
Что - это, в первую очередь, текст или двоичный файл, еще один вариант - многосекционное сообщение, каждая из секций которого тоже относится к одному из типов. Основное отличие - тексты, в общем и целом, предназначены для чтения человеком, независимо от используемого программного обеспечения, главное здесь - их читаемость. Двоичные файлы предназначены для передачи понимающей их программе или сами являющиеся программой, и главное здесь - передать их в неизменном виде. Разумеется, могут быть пограничные случаи, различие типов не абсолютное, но тем не менее классическая телеграмма "Шлите апельсины бочками. Братья Карамазовы" является чистым примером чистого текста, а исполняемый модуль программы, зараженный вирусом, - чистым примером передачи двоичного файла. И если двоичный файл самодостаточен, то текст, превращенный в последовательность байтов, неотделим от своей кодовой таблицы, или (языковой) кодировки.
Как - способ дополнительно закодировать превращенное в последовательность байтов содержание, чтобы его можно было передать по электронной сети, что может быть необходимо даже для текста и практически всегда необходимо для двоичных файлов, которые вполне могут содержать не только символы, не входящие в ASCII, но и управляющие коды (от 0 до 31), типа "возврата каретки" или "перевода строки". Этот способ тоже может быть назван кодировкой, но, в отличие от предыдущего абзаца, - транспортной кодировкой.
Изначальный стандарт на электронное сообщение разрешал исключительно 7-битные символы в сообщении, т.е. кодировку ASCII (American Standard Code for Information Interchange). Через некоторое время появился и устоялся стандарт MIME (Multipurpose Internet Mail Extensions), определяющий способы передачи через Интернет любых сообщений.
Но спектр встречающихся в жизни 7-битных транспортных кодировок шире "кодифицированного" в стандарте MIME. Все они, так или иначе, превращают произвольный двоичный файл (но, возможно, и обычный текст) в чисто 7-битное, не содержащее управляющих символов (а часто и пробелов) ASCII-сообщение, как правило, с постоянной длиной строки близкой к 60 символам. Обычно также закодированное сообщение содержит маркеры-указания типа кодировки.
Практически все современные версии почтовых программ умеют раскодировать практически все транспортные кодировки, за исключением BTOA. Поддержка транспортных кодировок появляется сейчас и в других категориях программ, в частности, последние версии WinZip свободно читает файлы в Base64. На редкость универсальным кодером/декодером является Windows Commander.
 |
-> |  |
-> |  |
-> |  |
-> |
| письмо | 1 | почтовая программа отправителя | 2 | почтовая система провайдера 1 | 3 | промежуточные узлы | 4 |
| -> | |
-> |  |
-> |  |
||
| 4 | почтовая система провайдера 2 | 5 | почтовая программа получателя | 6 | принятое письмо | 7 | |
Схема передачи электронного сообщения |
|||||||
В этой схеме под "письмом" понимается скорее зрительный образ, чем соответствующий файл - программа и компьютерная система получателя могут совершенно не соответствовать таковым у отправителя, не обязаны совпадать в этих системах и русские кодировки. Однако всё же считаем, что передаётся электронное письмо, т.е. некоторая последовательность символов, а не сам графический образ в виде картинки, иными словами, оставляем в стороне передачу факсов, телеизображений и тому подобные вещи. И при всем при этом полученное письмо должно соответствовать отправленному.
Есть два предельных случая во взглядах на электронную почту. Один - отправляя письмо, я хочу, чтобы оно, как телеграмма, было прочитано любым получателем, какая бы почтовая система у него ни была, другой: письмо - это сложное художественное сооружение, и я хочу, чтобы адресат получил в точности то, что я ему посылаю. И пусть для этого он будет обеспечен соответствующими средствами.
В российском Интернете сложился фактический (т.е. почти повсеместно принятый) стандарт электронной переписки, ориентированный в большей степени на первый случай. В виде своего рода формулы он выражается так: фиксируется что передается - чистый текст (не форматированный, не HTML), язык и кодировка - KOI8-R и как - транспортная кодировка тела сообщения отсутствует (8bit body), в заголовках разрешаются 8-битные символы, и они тоже не кодируются (8bit header). Наконец, требуется указывать эти данные в заголовке письма, т.е. оформлять его по стандарту MIME. В таком виде письмо должно уйти от "провайдера 1" и в таком же виде оно должно прийти к "провайдеру 2" (участки 3 и 4). На участках 1 и/или 2 письмо может как-то преобразовываться из исходного вида, удобного для отправителя, а на участках 5 и/или 6 - преобразовываться в вид, удобный получателю.
В начале эта схема замечательно работала (причем даже без MIME), пока основной операционной системой двуединого провайдера Relcom/Demos был UNIX, где КОИ-8 - "родная" кодировка (что, впрочем, справедливо не для всех клонов UNIX), а основной операционной системой пользователей (фактическим стандартом) был либо тот же UNIX (у пользователей "корпоративных"), либо DOS и пакет UUPC, работавший автоматически и сам справлявшийся со всеми перекодировками. За границу, правда, писать надо было латиницей, да и понятно - откуда в американском UNIX или DOS возьмутся русские буквы. Появившиеся (или ставшие известными) несколько позже провайдеры с терминальным доступом вполне адаптировались к этой схеме, обеспечивая перекодировку из DOS и в DOS для пользователей (на участках 2 и 5). Идиллическую картину нарушали только немногочисленные пользователи Macintosh'ей, у которых русская кодировка была своя и мало кому известная.
Потом начался период разброда и шатаний. Фактическим стандартом операционной системы пользователей становились, и вскоре стали разные версии Microsoft Windows. В них были свои программы терминального доступа и весьма ограниченная поддержка DOS-кодировки, в то же время разработанная в Microsoft новая кодировка для Windows (совместимая по кавычкам и т.п. символам с другими кодовыми страницами под Windows) была для провайдеров незнакомой и не поддерживаемой. Однако революция произошла несколько позже - когда начал победное шествие Интернет в нынешнем виде - в виде, главным образом, WWW, а фактическим стандартом стал полноценный IP-доступ, дающий непосредственный проход к большинству ресурсов Интернет и фактически уравнявший на этой схеме участок 2 и участок 3, а также 4 и 5 и тем самым - применительно к почте - возложивший ответственность за соблюдение стандартов на почтовые программы конечных пользователей. Программы же в лучшем случае знали две кодировки - us-ascii, если в сообщении не было 8-битных символов, либо ISO-8559-1, если они там были. И никаких перекодировок. Поэтому возникла задача внедрения KOI8-R в Windows, появились koi8-шрифты (почти все без псевдографики) и koi8-раскладки клавиатуры, что было не вполне удобно, не решало проблему корректного MIME-оформления, но хотя бы решало проблему с кодировкой и читаемостью. Однако постоянное недоумение пользователей в русле "зачем нам эта КОИ-8" заставило наиболее "близких к народу" провайдеров взять на себя часть проблем адаптации пользователей IP-доступа к стандартам и появились перекодирующие серверы, которые позволяли ограничиться в Windows обычной поддержкой русского языка: передаваемая русская почта перекодировалась из CP1251 в KOI8-R, а принимаемая - из KOI8-R в CP1251. При всех удобствах такой технологии, она очевидным образом является своего рода костылями, накладывающими жесткие ограничения на форматы и язык письма, к тому же не укладывается в интернетовские стандарты. Как правило, письма перекодируются независимо от значения charset в заголовке (и это правильно, учитывая что он обычно либо ISO-8859-1, либо KOI8-R для хакнутых программ, но в обоих случаях не соответствует реальной кодировке письма), что позволяет без ограничений посылать письма только на русском или английском языке и не позволяет менять кодировку русского письма даже при необходимости. Впрочем, несмотря на все обвинения провайдеров, прямой, неперекодирующий доступ всегда сохранялся, хотя иногда он исчезал из списка рекомендованных новым клиентам.
А ещё, через какое время распространились общедоступные программы, которые более или менее корректно сами умели работать с различными кодировками, в первую очередь Microsoft Internet Explorer версии 3, а затем 4, и наличие перекодирующих входов у провайдеров в сочетании с этими программами стало приводить к порче электронных писем. С другой стороны, большинство других почтовых программ либо также научились поддерживать несколько кодировок, либо появились методы вставить в них поддержку KOI8-R. Тем самым полезность перекодирующих серверов у провайдеров всё более снижалась, а их роль как дополнительного источника проблем всё возрастала.
Основным преимуществом KOI8-R является только то, что она представляет собой фактический стандарт и что наличие стандарта лучше, чем его отсутствие. Хотя ясно, что в связи с повсеместным распространением различных версий MS Windows все усиливается давление со стороны Windows-кодировки и ее победа в будущем не исключена. С ней меньше проблем в большинстве почтовых программ. Одно из реальных преимуществ Windows-кодировки именно в почте - пригодность для большинства языков с кириллицей, что не обеспечивается KOI8-R и привело к появлению украинских и белорусских клонов КОИ-8 (в частности, KOI8-U). На WWW-страничках уже сейчас Windows-кодировка явно оттеснила KOI8-R: вышеприведённая схема при попытке распространить её на WWW сокращается едва ли не до двух компьютеров - WWW-сервера и получателя с его программой-смотрелкой.
Преимущества KOI8-R как почтовой кодировки тоже понятны - это полная совместимость и наличие взаимно однозначного соответствия с русской DOS-кодировкой (одним из вариантов CP866), включая псевдографику. Тем самым обеспечиваются удобства для досовских пакетов UUPC, и, разумеется, для взаимодействия с ФИДО. По не вполне понятным причинам оказалось также, что встроить более или менее нормальную работу с KOI8-R в программы под Windows проще, чем сделать это для почти "родной" DOS-кодировки, к тому же (отвлекаясь от букв "Ё" и "ё") в KOI8-R и CP1251 русские буквы занимают одну и ту же область, поэтому всевозможные, даже многократные перекодировки друг в друга - в этой области - оказываются взаимно однозначными, так что большинство испорченных сообщений в принципе можно прочесть. Однако клоны КОИ-8, в частности KOI8-U (говорят, есть и KOI8-B), уже не подходят под стандартную перекодировку KOI8-R в DOS, в них отсутствует часть псевдографики, и их появление явно не на пользу КОИ-8, я бы даже расценил регистрацию KOI8-U как чрезвычайно сильный удар по статусу KOI8-R как "стандарта de-facto". И если DOS-кодировка отомрёт вовсе и потребность в псевдографике исчезнет, то реальных преимуществ у CP1251 окажется больше. За одним, правда очень важным, исключением - смена стандартов всегда процесс весьма болезненный.
Возвращаясь к обсуждению пути электронного письма, будем считать, что чаще всего сообщение портится на этапе 2 - внутри почтовой программы и провайдера отправителя. Если в эту систему входит еще многоуровневая (локальная) сеть, возможностей порчи становится больше. На этапах 3 и 4 письмо не меняется, а дальше свою лепту может вносить аналогичная система получателя на этапах 5 и 6, хотя и с меньшей вероятностью, поскольку в нее поступает обычно уже "скорректированный" вариант письма.
Тем самым все события происходят:
- Внутри почтовой программы-клиента, которая каким-то образом кодирует, оформляет - и декодирует письмо;
- В почтовой системе провайдера, в которой могут быть свои перекодирующие входы (перекодирующие прокси-серверы), превращающие популярные русские кодировки (windows, а mac) в KOI8-R, а при приёме, наоборот - превращающие KOI8-R в кодировку пользователя.
Огрубляя схему, мы, с одной стороны, имеем ситуацию у отправителя - возможный источник извращенных сообщений, а с другой - принятое письмо у получателя, результат, возможно, в извращенной кодировке.
Если выбрать неправильную перекодировку, например, письмо в DOS кодировке будет перекодировано функцией (win->koi), то по сети пойдет письмо не в KOI8-R, и мы получим извращенный источник. Очень похожая ситуация возникнет даже без каких-либо перекодировок, если в сети окажется письмо в Windows-кодировке (для дальнейших целей назовём такой источник "Windows-извращением"). Именно последний случай был довольно частым на начальном этапе распространения "Интернета под Windows". Получатель на другой стороне, если он тоже пользуется Windows, такое письмо, скорее всего, прочесть сможет, но что делать пользователю Macintosh, для которого письмо будет перекодировано функцией (koi->mac)? Если же получатель пользуется Windows и перекодирующим входом, то для него Windows-кодировка подвергнется преобразованию из KOI8-R в Windows, и результат уже никакой стандартной кодировке не будет соответствовать, его можно назвать "koi-to-win-извращением". Частый источник посылки Windows-извращений - некорректная работа с перекодирующим сервером. Если посылаемое сообщение предварительно перекодировано программой в 7-битное, например, в Quoted-Printable, то через почти любые win-прокси такое - чисто ASCII сообщение - пройдет неизменным, и только получатель обнаружит, что оно пришло не в той кодировке. Правда, если получатель тоже "под Windows" и его перекодировщик не слишком хитрый и не трогает 7-битные письма, он может ничего не заметить и с полным правом утверждать, что у него "всё читается".
Другой, одно время довольно частый вариант, встречается, когда пользователь работает под Windows и пишет письма, как он считает, в Windows-кодировке, а отправляет их через перекодировку win->koi (через win-прокси) у провайдера. Но новая версия умной программы, которую пользователь себе поставил, уже знает, что в сети должно быть KOI8-R и отправляет письмо в этой кодировке. В результате в сети имеем KOI8-R, перекодированное функцией (win->koi), что тоже не соответствует ни одной стандартной кодировке, такой источник назовем "Winproxy-извращением", результирующую кодировку - "win-to-koi-извращением". Именно в ней придут письма к получателю, который не пользуется перекодирующим сервером. Однако и в этом случае, если у получателя тоже Windows-перекодировщик, то сообщение будет перекодировано обратно функцией (koi->win) и окажется в исходной кодировке KOI8-R, так что его без проблем можно будет прочесть.
Отрадным свойством извращенных кодировок, описанных в предыдущих абзацах, является возможность восстановления испорченного письма - перекодировка между CP1251 и KOI8-R стандартна и взаимно однозначна в области 32 русских букв, занимающих в них одну и ту же область. И на практике все сообщения, за крайне редкими исключениями, оказываются в одной из четырех кодировок: KOI8-R, Windows (CP1251), win-to-koi или koi-to-win. Ситуация сильно осложняется, если лишним перекодировкам подвергаются другие варианты. Даже стандартизованная и полностью взаимно однозначная перекодировка между CP866 и KOI8-R на практике встречается в разных несовместимых и не всегда взаимно однозначных вариантах, а перекодировка между CP1251 и KOI8-R за пределами русских букв вообще толком не стандартизована, и восстановить, скажем, исходное сообщение в DOS-кодировке, подвергнутое такому преобразованию, простым способом не удастся, если удастся вообще. Так, соответствующий перекодировщик всё, что не входит в область русских букв, заменяет на "звездочки". В результате от DOS-сообщения, подвергнутого перекодировке (win->koi) или (koi->win), хоть как-то, пусть в перемешанном виде, сохраняется лишь половина алфавита, причём только маленькие буквы. Остальное теряется безвозвратно!
А теперь - как обстоит дело с MIME-сообщением? По идее, здесь проблем быть вообще не должно. Каждый фрагмент сообщения содержит указания, как именно он закодирован, и почтовая программа получателя, руководствуясь этими указаниями, восстанавливает первоначальный вид письма. Никакой перекодировки у провайдера здесь, казалось бы, не требуется (во избежание извращений). Тем не менее, реальность гораздо сложнее и хуже:
- Формат MIME должна понимать программа получателя, в ней должны быть также заложены использованные в сообщении типы MIME (не вполне стандартизованные), наконец, поскольку для передачи текста используется символьная кодировка (а не картинка), в ней должны быть соответствующие (русские) шрифты. При этом должен правильно изображаться, например, как фрагмент текста в KOI8-R кодировке, так и фрагмент текста в Windows-кодировке (если используется один и тот же шрифт - например, внутренней перекодировкой). Надо ли говорить, что программ, реализующих всё это - одна-две и обчёлся (по сути, претендентом может быть только MSIE начиная с версии 4).
- Кроме того, сообщение должно быть понято программой, не знающей про MIME вообще (большинство старых версий программ). А это фактически запрещает использование в сообщении кодировок, отличных от KOI8-R (как в одном, так и в разных фрагментах), тем более недопустима отправка разноязычных сообщений (скажем, русско-ивритско-арабско-грузинских).
- Отправляемое сообщение должно быть корректно оформлено в программе отправителя - указания на язык и кодировку (поле Content-Type и подполе charset) должны соответствовать использованным и не должны искажаться по пути. Этой возможности у многих программ тоже нет, к тому же очень часто корректность charset теряется на перекодирующих серверах.
Т.е. в целях совместимости MIME-сообщение должно подчиняться тем же правилам, что и без MIME. Однако программ, старающихся корректно обрабатывать MIME больше, поэтому наличие MIME-оформления является более предпочтительным, чем его отсутствие.
«Всемирная паутина» появилась и начала развиваться в Америке, поэтому вся система почтовых серверов была предназначена для работы с почтой англоязычных пользователей. Сначала по электронной почте отправлялись лишь текстовые сообщения, поэтому почтовые программы составлялись с использованием первой половины кодовой страницы — семибитной кодировки. Из-за этого те письма, в которых содержались символы с кодами, превышающими число 127, обрабатываться не могли. Чтобы они все же проходили через семибитные почтовые серверы, символы принудительно приводились к семибитному виду: обнулялся первый бит, указывающий на половину их кодовой страницы. Например, символ "е" (русская буква "е") переходил в "f", а символ "ш" — в "y".
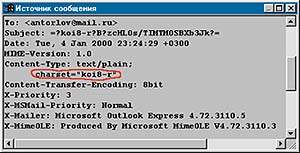 |
| На обоих экранах обведено указание на кодировку письма |
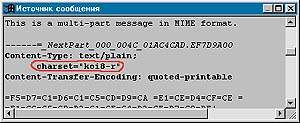 |
По-разному можно было выйти из сложившегося положения. Во-первых, что самое распространенное, писать письмо, используя транслитерацию, т. е. latinskimi bukvami. Хотя текст при этом выглядел некрасиво и плохо читался, сообщение всегда доходило в исходном виде. Поскольку не все почтовые серверы были семибитные, то была создана специальная кодировка под названием KOI-8 для электронной почты. Она отличалась тем, что на места кодов символов, превышающих 127, были проставлены русские символы, похожие по звучанию на английские, соответствующие кодам символов, номера которых были меньше на 128. Например, коды 225, 226, 227, 228 соответствовали символам "а", "б", "ц", "д", которые при семибитном преобразовании перешли бы в коды 97, 98, 99, 100 английских букв "a", "b", "c", "d". Слово "привет", написанное в такой кодировке, пройдя через семибитный почтовый сервер, преобразовалось бы в PRIWET.
Так как системы на основе Unix в основном были рассчитаны на работу с электронной почтой и международными сетями, новая кодировка стала стандартом для них. Чтобы облегчить переписку между пользователями разных типов ПК и ОС, KOI-8 была принята в качестве универсальной, т. е. любая почтовая программа обязана была уметь читать и отправлять в ней сообщения.
Наличие пяти различных кодировок для русского языка создавало определенные трудности, например потребовались специальные программы-перекодировщики. Однако самой большой проблемой стали российские почтовые серверы.
Казалось бы, нужно лишь одно — чтобы серверы обрабатывали сообщения в восьмибитных кодировках. Тогда тексты в любой кодировке всегда читались бы принимающей стороной с помощью программы, умеющей работать с ней. Но, увы, не все оказалось так просто. В некоторые почтовые серверы была встроена возможность автоматической перекодировки поступающих писем — вероятно, для определенной "стандартизации". Если поступало сообщение в кодировке Windows-1251 и сервер его так и воспринимал, то оно перекодировалось в KOI-8 и отправлялось дальше. Кодировка письма обычно указывалась в заголовке или прямо в тексте.
Русифицированная версия Microsoft Outlook Express по умолчанию для всех отправляемых сообщений ставит кодировку KOI-8 и отправляет их именно в ней. Однако некоторые почтовые программы могут делать ошибки, например письмо написано в KOI-8, а в заголовке письма проставляется, что оно имеет кодировку Windows-1251. Если такое письмо будет отправлено адресату, то оно не сможет сразу же правильно отобразиться в его почтовой программе — на экране появится мешанина из символов. Поскольку почти все почтовые программы позволяют просматривать одно и то же письмо в разных кодировках, то получатель прочитать его все же сможет, выбрав правильную кодировку. Но если письмо с не соответствующим содержанию заголовком попадет на перекодирующий почтовый сервер, то ситуация осложнится. По заголовку сервер решит, что раз оно написано в Windows-1251, как было указано, то его нужно перекодировать в стандартную для Сети (по мнению сервера и его создателей) кодировку KOI-8. Сообщение будет преобразовано из Windows-1251 в KOI-8, т. е. будут заменены соответствующие коды символов. Однако письмо-то уже изначально было в KOI-8! И что же получается? Автор письма написал фразу «Добро пожаловать», которая в KOI-8 записалась как «дНАПН ОНФЮКНБЮРЭ». А сервер снова перекодировал ее, но уже из Windows-1251 в KOI-8. В результате получилось: «Дмюом нмтчймачпщ», и понять что-либо стало уже невозможно. Если же на пути письма попалось несколько перекодирующих почтовых серверов, то его дешифрация становится крайне сложной задачей.
Изначально по электронной почте нельзя было пересылать вложенные файлы (обычно это архивы), которые представляют собой двоичные данные, т. е. не раскладываются на вразумительную последовательность символов. Безусловно, можно было принудительно разбить последовательность данных в файле на группы по восемь бит и попытаться перевести их в текст. Можно проделать подобный эксперимент, переименовав какой-либо исполняемый файл или архив в файл с расширением «.txt» и загрузив его в Word 6.0 или 97. Однако после преобразований пересылаемая программа вряд ли бы заработала, а архив открылся бы, ведь их код стал бы испорченным и практически не поддавался бы восстановлению. Поэтому были разработаны специальные системы вложений в почтовые сообщения, основанные на конвертации двоичных данных в набор символов с кодами от 33 до 127. Впоследствии они могут быть подвергнуты обратному преобразованию. Было разработано несколько таких систем, самые распространенные из них — uuencode и base64. Почтовая программа, умеющая работать с вложениями, перед отправлением письма конвертировала вложенные файлы в одну из таких кодировочных систем (помещая перед вложением соответствующее указание), а после получения письма превращала вложенный фрагмент в исходный двоичный файл.
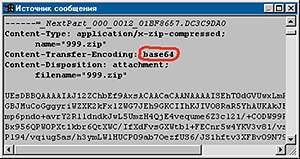 |
| Обведено указание на систему конвертации бинарных файлов |
Вот, например, фрагмент письма с вложением, просматриваемый с помощью функции Microsoft Outlook Express «Файл->Свойства->Подробно->Исходное сообщение».
К этому письму приложен архив 999.zip, а также указан способ конвертации вложения — base64. Дальше идет набор символов первой половины кодовой таблицы — можно с уверенностью утверждать, что он пройдет через любые почтовые серверы неизмененным. При получении такого письма Outlook Express распознает наличие вставки base64, отобразит вложенный файл на панели вложений и позволит сохранить его на жесткий диск или прочитать, подвергнув обратному преобразованию из base64.
Таким образом, из-за наличия пяти кодовых страниц для русского языка требуется обеспечить две возможности. Во-первых, чтение текста, написанного в соответствии с одной кодовой страницей, в ОС с другой кодовой страницей, во-вторых, расшифровку неоднократно перекодированных электронных писем. Чтобы решить эти проблемы, можно использовать специальные программы или компоненты программных пакетов.
К сожалению, однозначного ответа здесь нет, но стремиться следует всё-таки к соблюдению по возможности писаных и неписаных стандартов, а не к уклонению от них. Впрочем, при понимании, как все устроено, не запрещены и отклонения от этих рекомендаций, как и раньше, "древо жизни пышно зеленеет". Дальше учитываются два наиболее распространенных сейчас варианта работы с Интернет из-под Windows: без перекодирующего сервера, напрямую в KOI8-R, и через Windows-перекодирующий сервер, или win-proxy (перекодировки win->koi и koi->win).
Сообщения по русскоязычному сегменту сети:
- Вариант с MIME:
- Если не используется win-proxy - сообщения в KOI8-R, с 8-битным телом (не используется Quoted-Printable или Base64) и 8-битным заголовком (не используется кодирование заголовков), оформленные как MIME (указывается charset=koi8-r), с единственной секцией, содержащей сообщение.
- Если используется win-proxy - то же самое, но в кодировке Windows (CP1251), для большинства нынешних перекодирующих серверов в заголовке должен указываться тот же charset=koi8-r.
Желательно не использовать русских букв в Subject.
- Вариант без MIME (менее предпочтительный):
- Если не используется win-proxy - сообщения в KOI8-R, 8-битные, без MIME-оформления (и без перекодировки как тела, так и заголовка);
- Если используется win-proxy - то же самое, но в кодировке Windows (CP1251).
Желательно не использовать русских букв в Subject.
Сообщения за пределы русскоязычного сегмента сети:
Здесь не следует надеяться на наличие не MIME-программы (скажем, терминальной), понимающей русский язык, так что у адресата должна быть графическая операционная система (часто таковой являются все те же Windows-*) и MIME-совместимая почтовая программа. Пожалуй, наилучшим выбором для большинства сейчас стал Outlook Express. Кроме того, в системе получателя должны иметься русские шрифты, желательно как в кодировке Windows, так и в кодировке KOI8-R. Более желательным кодировать тело сообщения Quoted-Printable или другим допустимым способом. При этом правда, теряется возможность пользоваться перекодирующими серверами. И, естественно, русские буквы в Subject становятся крайне нежелательными.
Всё дело в том, что для почты у нас принято использовать кодировку KOI8-R, а для веба - Win-1251 (ANSI) - так, и выходит - мы шлём с сайтов в win-1251, а почтовые программы открывают его как KOI8-R...
- Если получаете письмо:
- КАК ОПОЗНАТЬ:
Вместо русских букв символы псевдографики. Скорее всего, это файл в кодировке koi-8. КАК РАСКОДИРОВАТЬ:
Если Вы пользуетесь программой Outlook Express, то обычно она правильно отображает сообщения, написанные на разных языках. Однако некоторые сообщения, особенно из групп новостей, имеют неверные сведения о кодировке (либо эти сведения отсутствуют). В таком случае возможно неверное отображение сообщения. Для того, чтобы это исправить выберите меню "Вид" в окне читаемого сообщения, укажите на пункт "Кодировка" и выберите нужную кодировку. Необходимо, чтобы на локальном компьютере была установлена поддержка данного языка. (Можно загрузить необходимые файлы из "международного" раздела веб-узла обозревателя Internet Explorer).- Если отправляете письмо с помощью PHP:
- КАК ОПОЗНАТЬ:
После отправки письма с русскими буквами в правильной кодировке с помощью PHP, на почту людям приходит абракадабра. КАК РАСКОДИРОВАТЬ:
Можно на самой веб-странице использовать кодировку KOI8-R, но в этом случае у некоторых посетителей могут возникнуть проблемы с кодировкой на самой странице.Проще перекодировать само сообщение, тем более в PHP предусмотрена стандартная процедура -
convert_cyr_string(string str, string from, string to);
Как Вы уже, наверное, догадались, функция перекодирует текст, содержащийся в переменной $str из кодировки $from в кодировку $to. Указание кодировки происходит посредством символов латинского алфавита, вот доступные параметры и соответствующие им кодировки:
Как видно из таблицы, в нашем случае, перед отправкой сообщения, содержащегося в переменной $msg, его нужно перекодировать из w в k (из Win-1251 в KOI8-R), это выглядит так:k KOI8-R w Win-1251 i ISO8859-5 a X-CP866 d X-CP866 m X-Mac-Cyrillic
$msg = convert_cyr_string ($msg,w,k);
вот и все, теперь можно спокойно отсылать наше письмо.

Сомневаетесь в выборе хостинга? Хотите проверить, прежде чем платить? eServer.ru предоставляет Вам эту возможность! SSL, MySQL, SSI, PHP, PERL, C++, JSP, неограниченный трафик, домен бесплатно и многое другое.
Выберите нас, Вы не пожалеете об этом выборе! Узнать больше...